入力データに基づいた繰り返し処理:Rhino+Grasshopperを用いて
Rhino+Grasshopperを使用するとき、同じ作業を繰り返さなくてはならないことあります。
繰り返し作業が10回以下ならばGrasshopperの手動クリックでもいいでしょうが、20回を超えたり、1回の処理に10分以上かかる場合は、入力データを元にした半自動の繰り返し処理を作る方が簡単です。
ここでは、入力データに基づいた繰り返し処理の設定方法を説明します。
この繰り返し処理には、Anemoneというアドオンが必要です。
Grasshopperを使う上ではアドオンを活用することが最も重要です。なぜなら、GrasshopperはMcneelグループの認証なしに、誰にでもアドオン作成の扉を開いているからです。
Anemoneを一言でいうと、「LOOP」になるでしょう。

基本的にアネモネでは、特定の範囲(開始から終了まで)をループするように設定し、そのループしたサイクルを必要な条件に合うまで繰り返していきます。
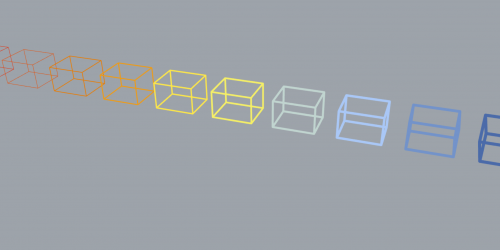
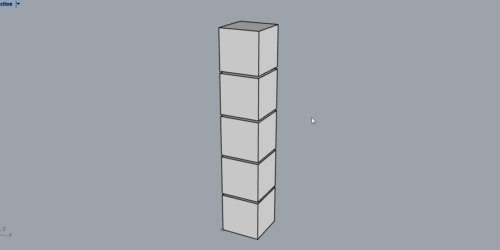
繰り返し作業の簡単な例を見てみましょう。この例では、Rhinoの別ファイルで平面図を元にジオメトリを作成しています。
理想的なBIMの考え方からすると、3Dモデルを事前に作成しておき、それを元に2Dの図面を作成することになります。ただ実務の場合は、この例のように、2D図面(平面図、立面図)を元に3Dモデルを作成してほしいという要望が出ることが多いです。
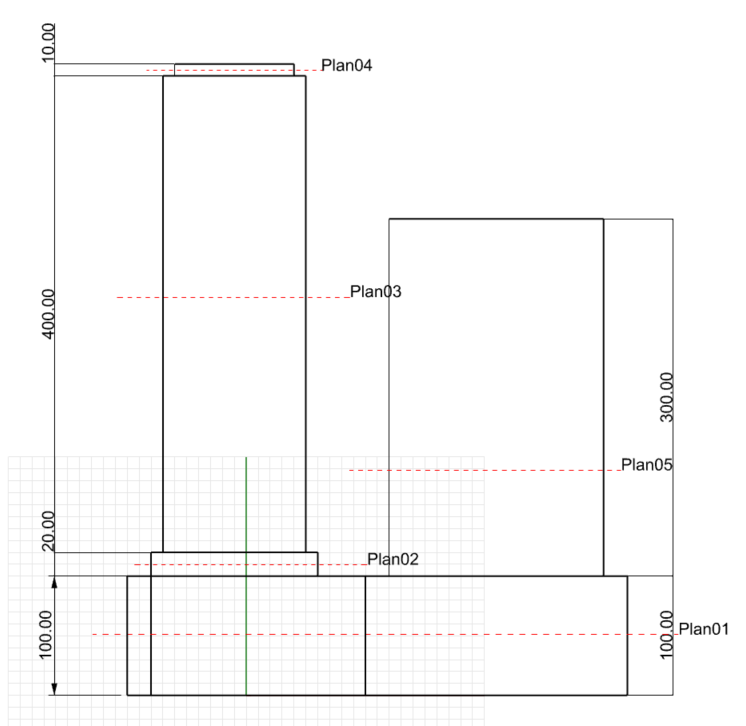
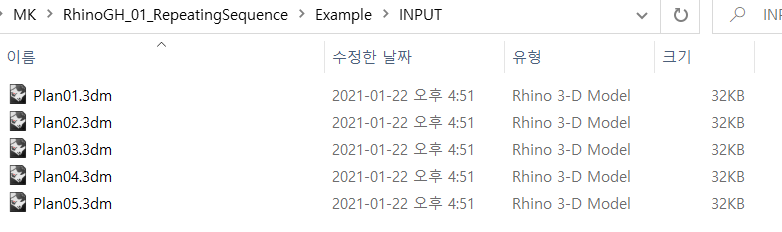
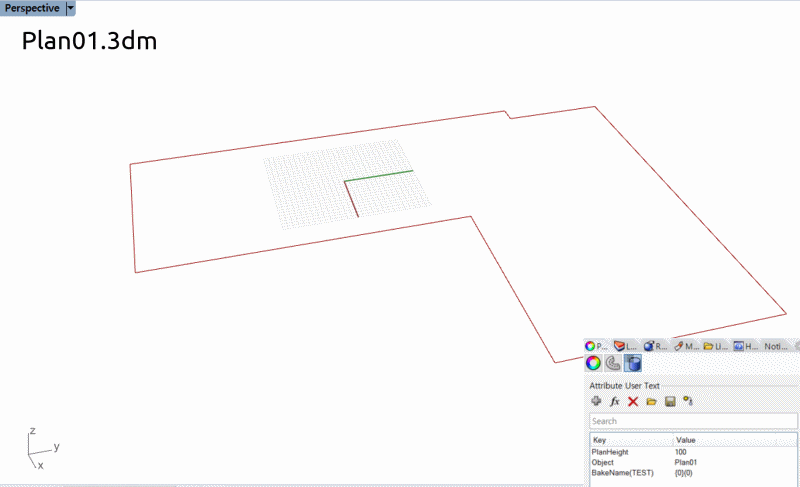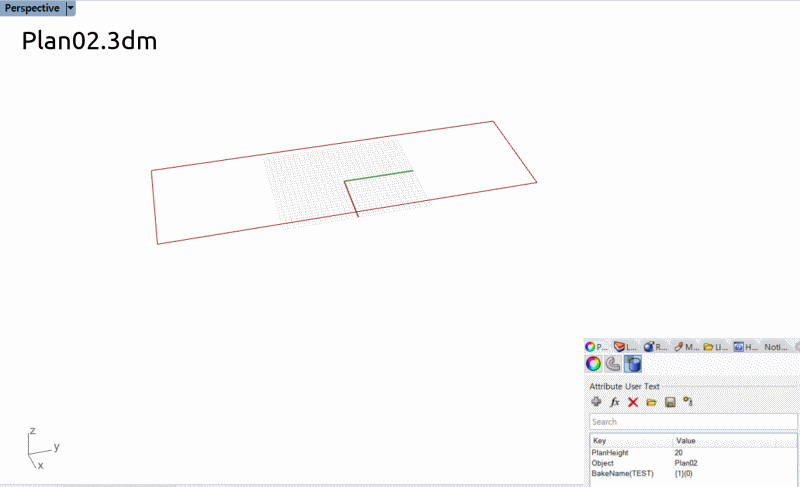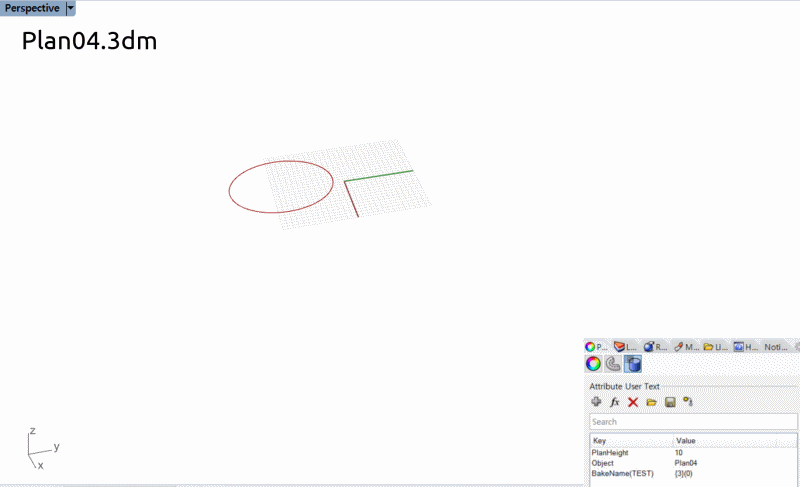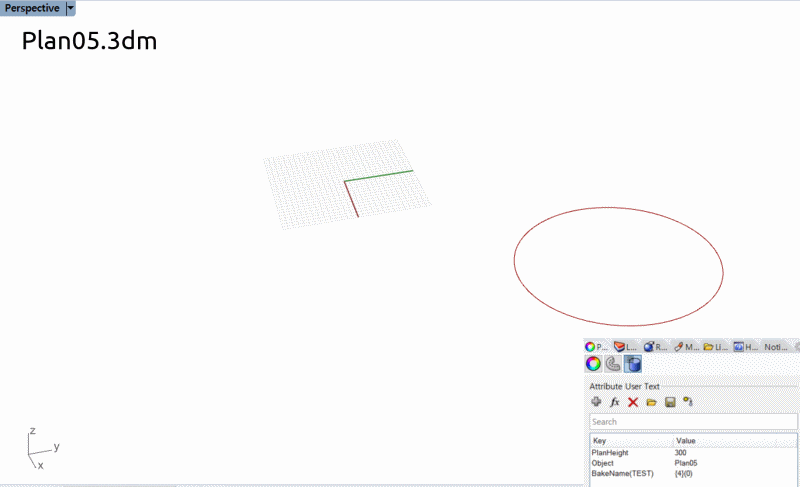
この場合は別々のRhinoファイルに保存されたフロアごとの外形線(Attributeに高さ情報が含まれている)
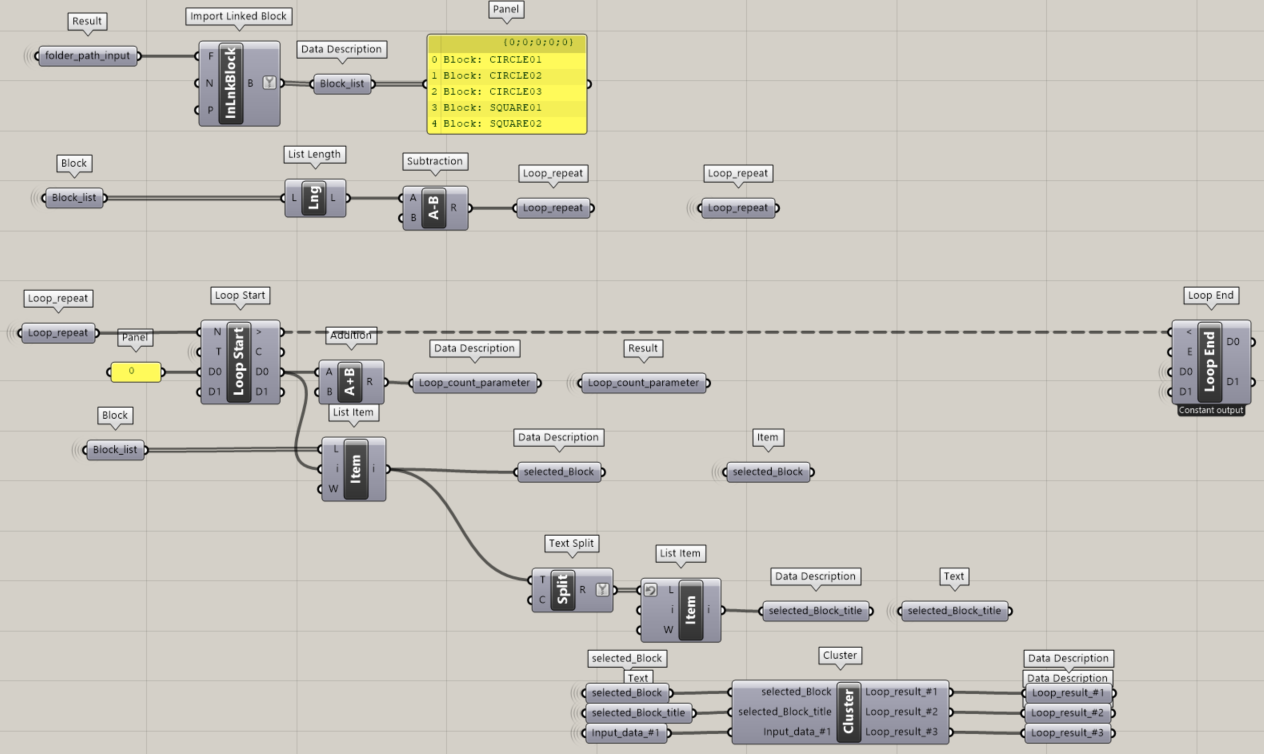
Grasshopperはビジュアルコーディングではありますが、コメントが書かれていないと理解しにくいものになります。書き加えると以下のようになります。
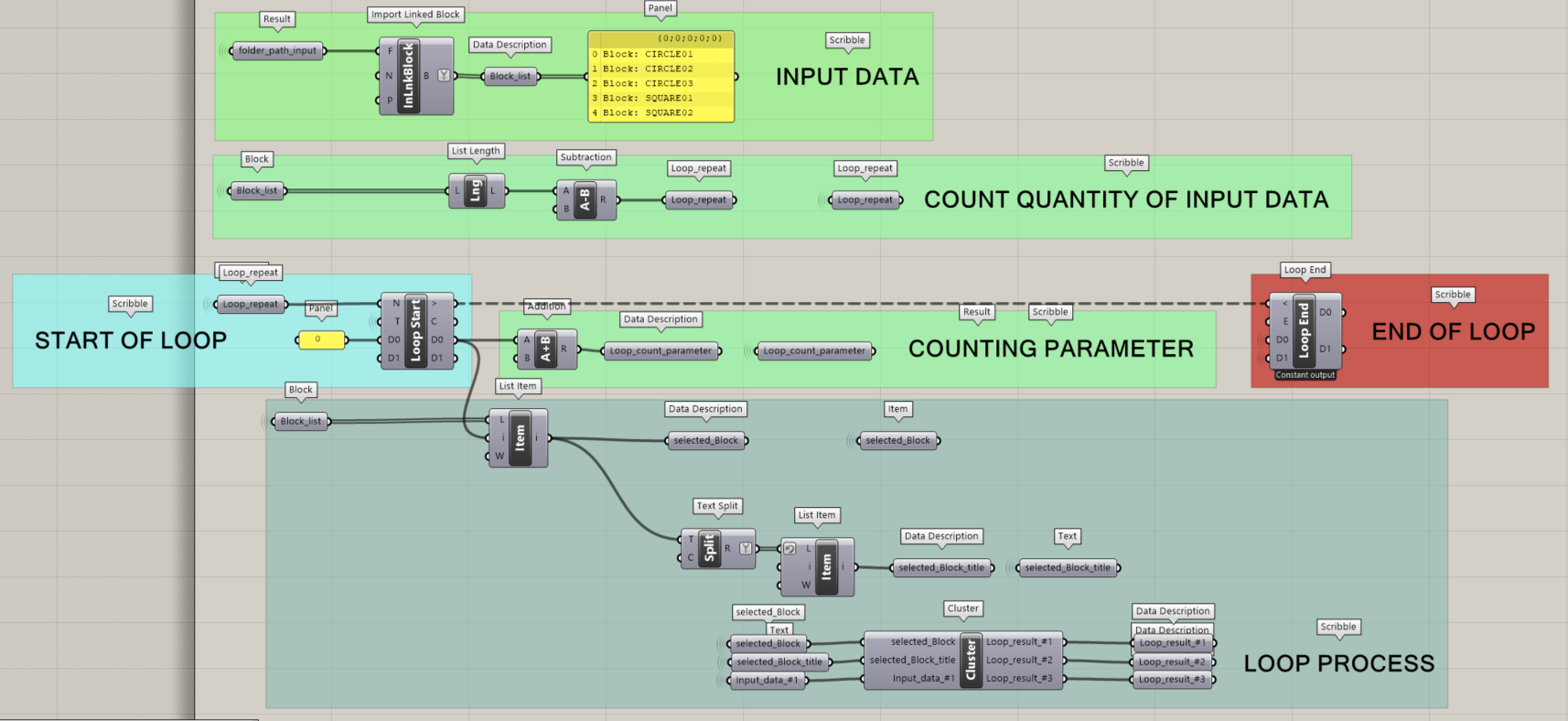
ご覧のようにINPUT DATAの部分には、繰り返しデータを挿入しています。
そのすぐ下の”COUNT QUANTITY OF INPUT DATA”では、繰り返しが必要なデータの数をカウントし、それを元に微調整をしています。

Grasshopperではリストの先頭が “1 “ではなく “0 “になっているので、長さの抽出が必要です。
以下ではアネモネの作業手順を示しています。
- 入力データを読み込む
- 入力データに基づいて、何回繰り返したかをカウント
- ループ開始条件、ループ終了条件、COUNTING PARAMETERを設定
- COUNTING PARAMETER が最後の COUNTING 番号に合うまでループ処理をする
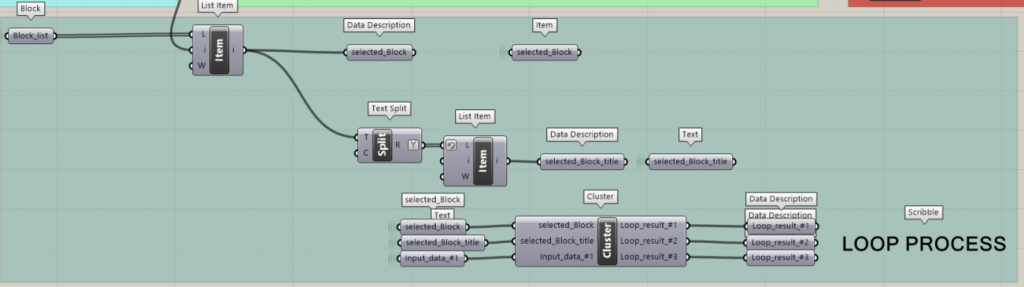
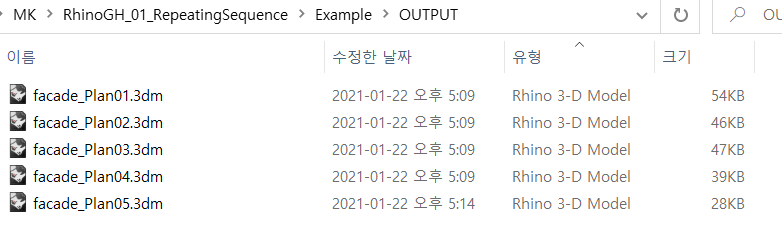
このLOOP PROCESSでは、INPUT DATAだけが変化します。そのため、file#1を挿入して、次にfile#2を挿入して、最終的にfile#5を挿入していると考えることができるでしょう。
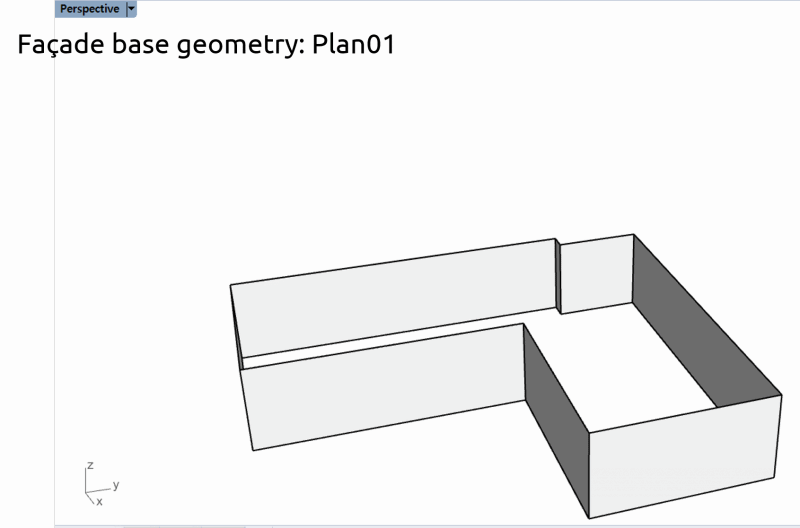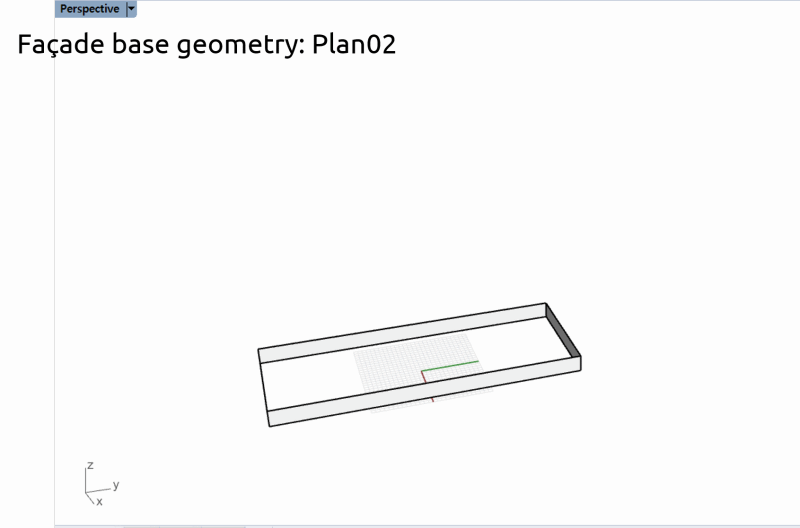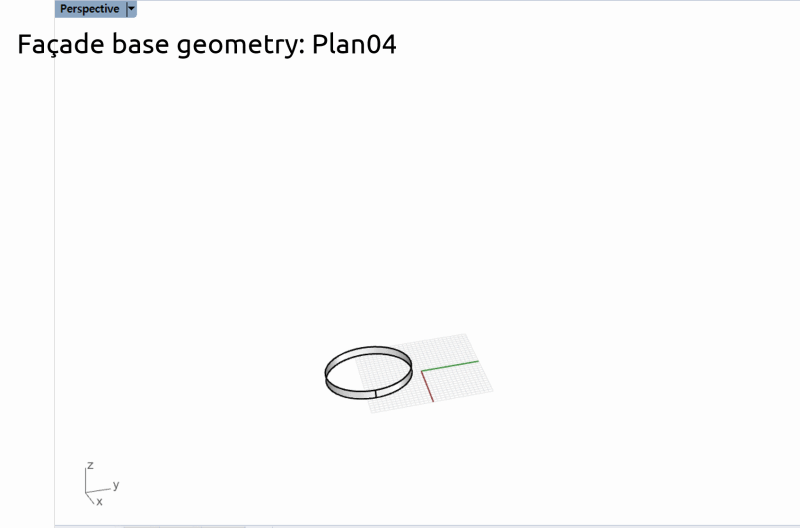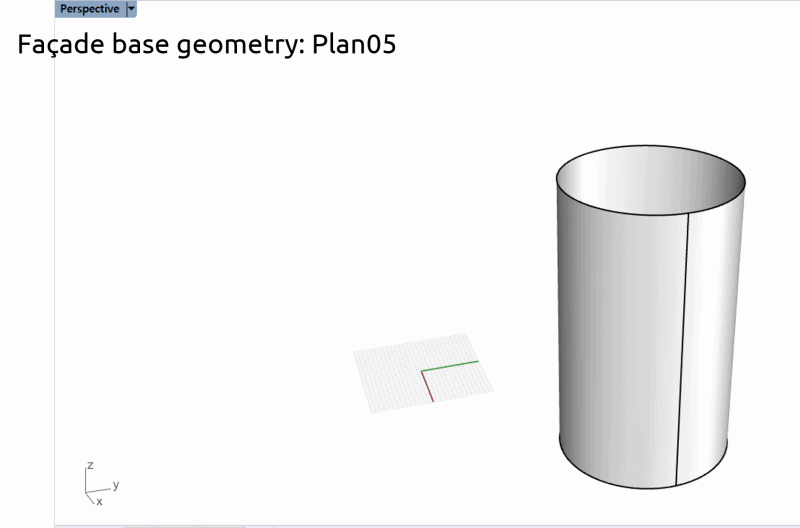
平面図ごとに異なるファイルで保存されている
このLOOP PROCESSの代わりを使わなくても、同じ結果になるのではないかと考える人もいるでしょう。しかし、サイズの異なるデータのエクスポートやデータ構造の変更などの作業を、Grasshopperの一度の作業で並行して行うことは簡単ではありません。
そのために「繰り返し」が必要になります。同じロジック/コードの繰り返しの結果を、別々のデータに保存することができるのです。
もちろんAnemoneを注意深く使えば、この「繰り返し」を「進化的」な方法にすることもできます。それが次回の記事のテーマになるでしょう。